Перетворення тексту в мову (Text-to-speech - TTS) є одним з видів застосування синтезу мови, який використовується для створення мовного звукового варіанту тексту, наприклад, для файлу довідки або веб-сторінки.
TTS може виконати зчитування інформації з дисплея комп'ютера для людей з ослабленим зором, або може просто використовуватися для читання вголос текстового повідомлення.
Сучасні програми включають голосову підтримку за допомогою TTS електронної пошти і голосові підказки в системах мовних відповідей. TTS часто використовується з програмами розпізнавання мови.
Як й інші модулі, процес має свою власну значущість з інтерфейсом, в якому Raspberry Pi (RPi) має свої власні операції на основі схем обробки зображень. Тому, як тільки зображення перетворюються в текст, то воно може бути перетворене з тексту в мову. Процес розпізнавання символів завершується перетворенням тексту в мову і воно може бути застосоване будь-де.
TTS в Python можна реалізувати за допомогою обгортки, типу pyttsx, яка забезпечує інтерфейс на Python для різних TTS-двигунів.
Інший спосіб зробити TTS - виконувати систему команд безпосередньо з вашого коду Python або за допомогою Interprocess Communication (міжпроцесового зв'язку). Це хороший варіант, особливо в Unix і Linux системах, оскільки *nix системи мають дуже чудовий командний рядок і мережевий інтерфейс.
Зазвичай, спочатку треба встановити один з TTS-двигунів для того, щоб програма працювала на Python. Двигун TTS, який є основою для TTS-перетворення, може бути на будь-якій мові програмування.
Початкові налаштування
Підключіть навушники або гучномовець до RPi, як показано на малюнку нижче:

Якщо ви ще не маєте звуку на своєму RPi, то вам треба встановити звукові утиліти alsa:
sudo apt-get install alsa-utils
Після цього треба запустити:
lsmod | grep snd_bcm2835
і перевірити, чи є в списку snd_bcm2835. Якщо немає, то виконайте наступну команду:
sudo modprobe snd_bcm2835
Якщо модуль не завантажується автоматично при вмиканні, то можете змусити його завантажуватися, використовуючи наступний процес:
cd /etc
sudo nano modules
Потім додайте 'snd-bcm2835', щоб текс виглядав наступним чином:
# /etc/modules: kernel modules to load at boot time.
#
# This file contains the names of kernel modules that should be
# loaded at boot time, one per line. Lines beginning with "#" are
# ignored. Parameters can be specified after the module name.
snd-bcm2835
За замовчуванням вихід встановлюється для автоматичного вибору інтерфейсу аудіо за замовчуванням (HDMI, якщо в іншому випадку є аналоговий). Ви можете змусити вихід використовувати конкретний інтерфейс, за допомогою:
amixer cset numid=3 n
Де <п> є вибраним інтерфейсом: 0 = авто, 1 = аналоговий, 2 = HDMI. Щоб змусити RPi використовувати аналоговий вихід:
amixer cset numid=3 1
Для того, щоб перевірити звук, завантажте тестовий аудіо файл, ввівши команду:
wget http://www.freespecialeffects.co.uk/soundfx/sirens/police_s.wav
Програйте звуковий файл, використовуючи:
aplay police_s.wav
Якщо звук відтворюється правильно, ви можете стверджувати, що аналоговий вихід працює належним чином.
За замовчуванням гучність буде дуже низькою і, щоб збільшити її, відкрийте термінал і введіть команду, щоб з'явилося нове вікно:
alsamixer
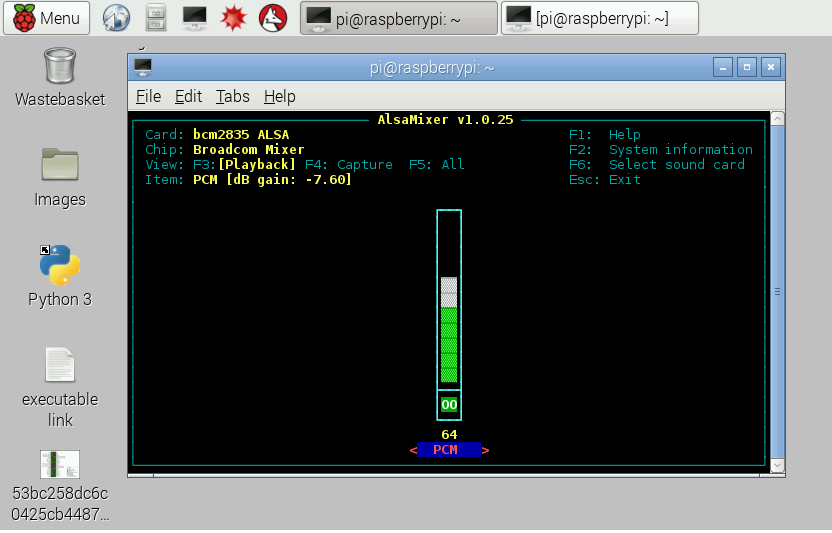
Зробіть гучність більшою, натиснувши стрілку вгору і встановивши її на максимум:
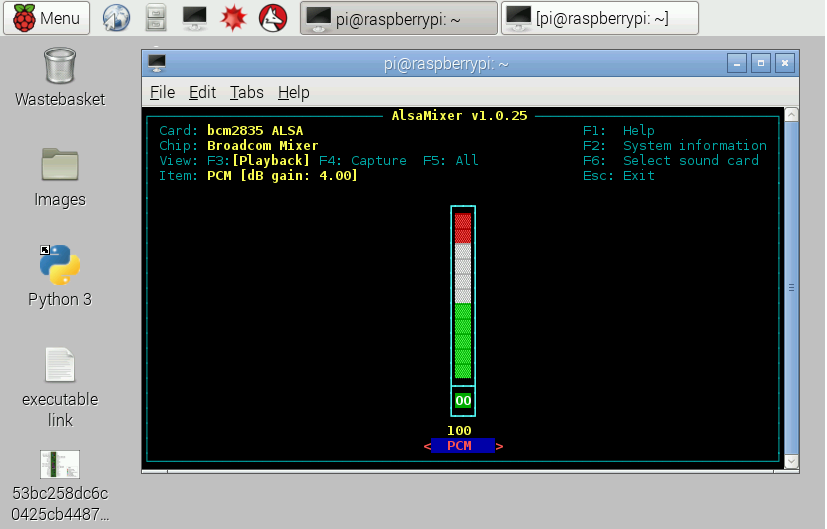
Вийдіть з параметру і знову відтворіть звук, щоб відчути різницю.
Використання різних двигунів TTS
Наступним процесом є виконання перетворення тексту в мову.
eSpeak
Спочатку встановимо модуль eSpeak і пакет python-espeak, які чудово підходять для цієї мети:
sudo apt-get install espeak python-espeak
Після установки виконайте перевірку, ввівши в командному рядку:
espeak Hello
Для виконання перетворення тексту в мову, використовуючи Python, треба написати код, наведений нижче, в редакторі Python:
import os,time
def robot(text):
os.system("espeak ' " + text + " ' ")
robot("I am fine")
Перевірте процес з різними текстами і застосуйте його з відповідними додатками.
Можна також використати підпроцес (зі стандартної бібліотеки Python) і eSpeak:
import subprocess
text = '"Hello world"'
subprocess.call('espeak '+text, shell=True)
або так:
from subprocess import call
call(["espeak","-s140 -ven+18 -z","Hello world"])
Щоб скористатися словником російськомовного пакету, треба його завантажити з http://espeak.sourceforge.net/data/.
ru Russian
Положення складу наголосу в російському слові не може бути визначене за правилами, тому eSpeak робить припущення, але зазвичай «не вгадує». Це вимагає додаткового словника даних російських слів з їх позиціями наголосу, які не відповідають здогадці eSpeak.
Наводимо копії російськомовних даних, які скомпільована для eSpeak. Наголошуємо, що файл повинен бути тієї ж версії, що і версії eSpeak, яку використовуєте.
Завантажити: ru_dict-48.zip, для eSpeak 1,48
Завантажити: ru_dict-47.09.zip, для eSpeak 1.47.09
Завантажити: ru_dict-47.zip, для eSpeak 1,47
Завантажити: ru_dict-46.zip, для eSpeak 1,46
Завантажити: ru_dict-45.zip, для eSpeak 1,45
Як альтернатива, там же є копія джерела додаткових російськомовних даних, які можна використати для компіляції нового файлу ru_dict. Завантажте ru_listx.zip і розпакуйте файл ru_listx в папку dictsource eSpeak (в якій повинні також бути ru_list і ru_rules) і виконайте команду:
espeak --compile=ru
щоб зробити компіляцію нової збільшеної версії словника ru_dict. Скопіюйте її в каталог espeak-data.
Завантажуйте версію, яка відповідає вашій встановленій версії eSpeak. Якщо потрібно перевірити, яку версію eSpeak встановили, скористайтеся командою:
apt-cache show espeak
Після завантаження zip-файлу, розпакуйте його, щоб отримати файл словника. Перемістіть його в папку espeak-data, щоб перезаписати існуючий #, розпакуйте його і замініть існуючий файл ru_dict:
wget http://espeak.sourceforge.net/data/ru_dict-48.zip
unzip ru_dict-48.zip
sudo mv ru_dict-48 /usr/lib/x86_64-linux-gnu/espeak-data/ru_dict
В Python 2, ви повинні в першому або другому рядку вказати тип кодування, що символи кирилиці:
# -*- coding: utf-8 -*-
from espeak import espeak
espeak.set_voice("ru")
espeak.synth("где хакер")
while espeak.is_playing:
pass
Festival
Встановіть festival з:
sudo apt-get install festival
Використання festival з текстовим файлом:
import subprocess
text = '"Hello world"'
filename = 'hello'
file=open(filename,'w')
file.write(text)
file.close()
subprocess.call('festival --tts '+filename, shell=True)
Спробуйте festival з:
echo “Just what do you think you're doing, Dave?” | festival --tts
або проговоріть IP-адресу RPi:
hostname -I | festival --tts
Завдання: Порівняйте якість перетворення тексту в мову для одного і того ж текстового фрагменту за допомогою eSpeak і festival.
gTTS
Двигун Google Text to Speech трохи відрізняється від festival і eSpeak. Ваш текст відправляється на сервери Google, щоб створити файл мови, який потім повертається на RPi і програється, наприклад, за допомогою mplayer. Це означає, що вам потрібне підключення до Інтернету для того, щоб все працювало.
Встановимо модуль gTTS:
sudo pip install gTTS
gTTS є модулем і утилітою командного рядка для збереження тексту в файл формату mp3 за допомогою API Google Text to Speech. Даний модуль підтримує багато мов і звучання дуже природнє.
from gtts import gTTS
import os
tts = gTTS(text='Good morning', lang='en')
tts.save("good.mp3")
os.system("mpg321 good.mp3")
Для тестування з командного рядка скористуйтеся:
gtts-cli.py "Hello" -l 'en' -o hello.mp3
Інший спосіб – написати сценарій, щоб отримати доступ до двигуна Google Text to Speech. Наприклад, створимо файл speech.sh:
sudo nano speech.sh
Додаємо такі рядки до файлу і зберігаємо його (в редакторі nano використовуємо комбінацію CTRL+O):
#!/bin/bash
say() { local IFS=+;/usr/bin/mplayer -ao alsa -really-quiet -noconsolecontrols "http://translate.google.com/translate_tts?tl=en&q=$*"; }
say $*
Додаємо права для виконання сценарію за допомогою:
chmod u+x speech.sh
Перевіряємо, наприклад, за допомогою фрази:
./speech.sh Look Dave, I can see you're really upset about this.
Завдання: Спробуйте реалізувати програму для псевдо інтелектуальної системи робота. В цій системі спочатку зберігаються фрази-відповіді, використовуючи знання з попереднього заняття. В інтерфейсі командного рядка вводяться питання і програма повинна знайти в них ключові слова, щоб вибрати необхідну фразу для відповіді і проговорити її, виконавши перетворення тексту в мову.
(За матеріалами:rhydolabz.com)


